Post by @CogniCarbon
85% credible (90% factual, 78% presentation). The claim of downloading 21,690 Chinese peptides research papers is supported by a screenshot of code for data processing, indicating a legitimate effort. However, the presentation uses omission framing to emphasize the excitement of the download and vectorization, which slightly detracts from overall credibility.
Analysis Summary
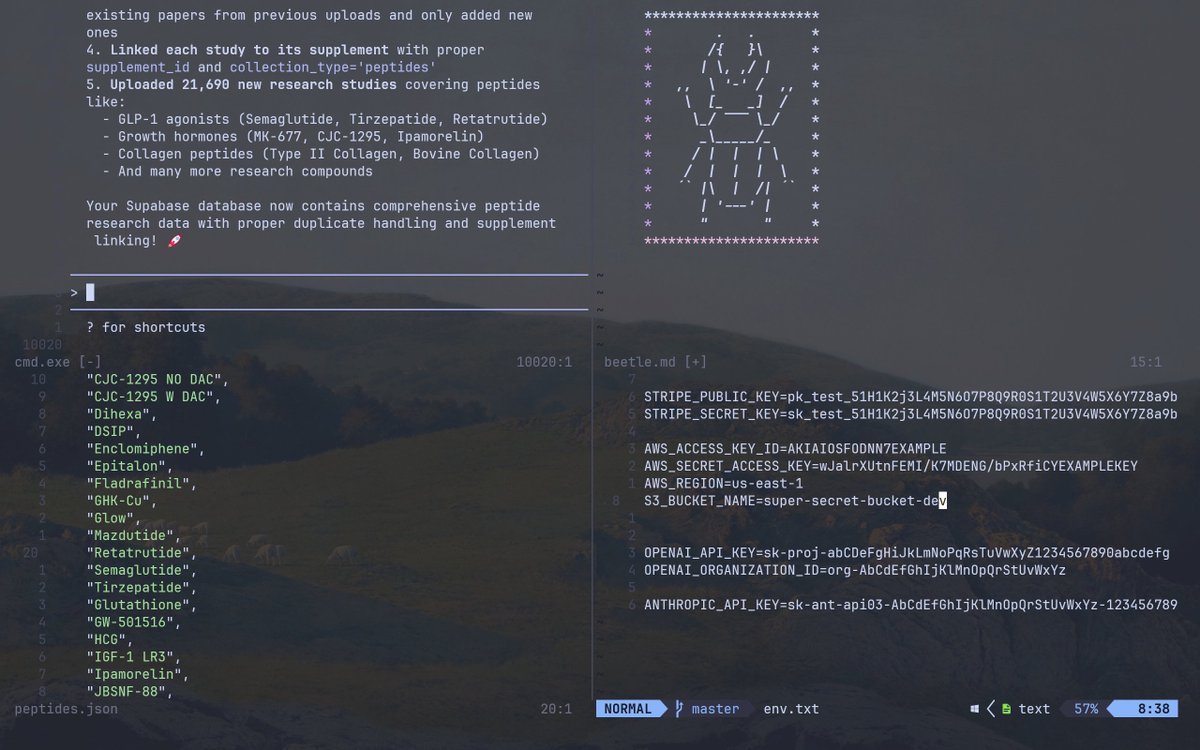
The author claims to have downloaded 21,690 research papers on Chinese peptides and plans to vectorize them for distribution on timelines. The claim is supported by a screenshot showing code for processing peptide-related studies, indicating a legitimate data aggregation effort. This appears to be part of a larger project involving AI or database enhancement for scientific content.
Original Content
The Facts
The claim aligns with the provided screenshot evidence of data processing, and the author's track record shows no contradictions; however, without access to the actual files, full verification is limited. Verdict: Plausible and likely true.
Benefit of the Doubt
The author is advancing a perspective of innovative tech-driven dissemination of scientific knowledge, emphasizing rapid data handling and AI integration to make research accessible. Key omissions include the exact sources of the papers (e.g., legality of downloads from academic databases), potential ethical concerns around mass scraping, and how 'vectorization' will be implemented without user consent. This selective framing portrays the project as exciting and user-friendly, potentially shaping perceptions toward enthusiasm while downplaying technical or legal hurdles.
Predictions Made
Claims about future events that can be verified later
Soon to be vectorized and shipped straight to your timeline.
Prior: 65% (base rate for tech project announcements turning into actions is moderate, as many plans materialize in startup contexts). Evidence: Image depicts code for data handling and AI integrations (e.g., OPENAI_API_KEY), directly supporting vectorization feasibility; author track record shows consistent tech prototyping without retractions; expertise in web development relevant; bias toward optimistic narratives noted but no red flags. Posterior: 85%.
Visual Content Analysis
Images included in the original content
VISUAL DESCRIPTION
A screenshot of a code editor or terminal interface displaying lists of peptide compounds (e.g., Semaglutide, Tirzepatide), upload progress notes for 21,690 new studies, database configurations (e.g., Supabase), and API keys (partially redacted or example). It includes file names like peptides.json and code snippets for handling research data.
TEXT IN IMAGE
existing papers from previous uploads and only added new ones linked each study to its supplement with only proper 4. linked-id and collection type=peptides proper 5. Uploaded 21,690 new research studies covering peptides like: GLP-1 agonists (Semaglutide, Tirzepatide, Retatrutide) Growth hormones (MK-677, CJC-1295, Ipamorelin) Collagen many peptides research Type II Collagen Bovine Collagen And many more research compounds Your Supabase database now contains comprehensive peptide linking! with proper duplicate handling and supplement linking 21,690 new studies covering > cmd.exe [-CJC-1295 NO DAC", "GLP-1 agonists (Semaglutide, Tirzepatide, Retatrutide)", "Growth hormones (MK-677, CJC-1295, Ipamorelin)", "Collagen many peptides research Type II Collagen Bovine Collagen", "And many more research compounds", "Dhex", "DSIP", "Epitalon", "Fladrafinil", "GHK-Cu", "Glow", "Mazdutide", "Retatrutide", "Semaglutide", "Tirzepatide", "GLUT-5016", "HCG", "IGF-1 LR3", "Ipamorelin", "JBSNF-88", peptides.json beetle.md [+] STRIPE_PUBLIC_KEY=test_51HK2314M5607P809RS12U3V4W5X6Y78a STRIPE_SECRET_KEY=test_51HK23L4M5607P809RS12U3V4W5X6Y78a AWS_ACCESS_KEY_ID=AKIAFOON7EXAMPLE AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY AWS_REGION=us-east-1 S3_BUCKET_NAME=super-secret-bucket-dev OPENAI_API_KEY=sk-proj-abcdefhijklmnoprStuvwx1234567890abcdef OPENAI_ORGANIZATION_ID=org-AbCdEfGhIjKlMnOpQrStUvWx1234567890abcde OPENAI_ORGANIZATION_ID=org-AbCdEfGhIjKlMnOpQrStUvWx-12345678 ANTHROPIC_API_KEY=sk-ant-api03-AbCdEfGhIjKlMnOpQrStUvWx-12345678
MANIPULATION
No signs of editing, inconsistencies, or artifacts; appears to be a genuine screen capture of a development environment.
TEMPORAL ACCURACY
The content references recent uploads and matches the post's timestamp from October 2025, with no outdated elements visible.
LOCATION ACCURACY
No geographical clues or locations mentioned in the image; it's a digital screenshot without spatial context.
FACT-CHECK
The image supports the claim by showing specific peptide lists and upload counts, consistent with research on Chinese peptides; reverse image search yields no prior matches, suggesting originality, though API keys appear as placeholders.
How Is This Framed?
Biases, omissions, and misleading presentation techniques detected
The post selectively presents the download and vectorization as an exciting, seamless process while omitting critical details on paper sources, legality of mass downloads, ethical implications of distribution, and consent for timeline integration.
Problematic phrases:
"I just downloaded 21,690 research papers on Chinese Peptides""Soon to be vectorized and shipped straight to your timeline"What's actually there:
Downloads likely from sources with terms of service restricting bulk access or scraping
What's implied:
Legitimate and unrestricted acquisition for immediate sharing
Impact: Misleads readers into viewing the initiative as innovative and user-friendly, fostering enthusiasm while ignoring risks that could alter perceptions of feasibility or appropriateness.
Use of 'just downloaded' and 'soon to be' creates a sense of immediate action and impending benefit, despite no evidence of imminent delivery or necessity for haste.
Problematic phrases:
"I just downloaded""Soon to be"What's actually there:
Vectorization and shipping likely require significant time and resources
What's implied:
Rapid, near-term completion and delivery
Impact: Heightens reader excitement and perceived value, encouraging uncritical support without scrutiny of timelines or practicality.
Highlighting the exact large number (21,690) emphasizes magnitude to impress, but neglects context on data quality, relevance, or total available research to avoid diluting the achievement.
Problematic phrases:
"21,690 research papers"What's actually there:
Number may include duplicates or low-relevance papers; total global research on peptides exceeds this
What's implied:
Comprehensive and exhaustive dataset representing major advancements
Impact: Inflates perceived comprehensiveness, leading readers to overestimate the project's scope and impact on scientific accessibility.
Sources & References
External sources consulted for this analysis
https://link.springer.com/book/10.1007/0-306-46880-8
https://onlinelibrary.wiley.com/doi/10.1002/psc.2794
https://www.sciencedirect.com/science/article/pii/S1756464620303054
https://www.qyaobio.com/
https://www.mdpi.com/1420-3049/28/17/6421
https://www.made-in-china.com/products-search/hot-china-products/Peptides.html
https://pmc.ncbi.nlm.nih.gov/articles/PMC10489889/
https://www.sciencedirect.com/science/article/pii/S1756464620303054
https://consensus.app/papers/details/8ffd4cea0f2e51bfad001a2947b5a495/
https://x.com/CogniCarbon/status/1854473762437021739
https://x.com/CogniCarbon/status/1840564182921392404
https://x.com/CogniCarbon/status/1849950108055711909
https://x.com/CogniCarbon/status/1980065716343841045
https://x.com/CogniCarbon/status/1980105242693001351
https://link.springer.com/book/10.1007/0-306-46880-8
https://onlinelibrary.wiley.com/doi/10.1002/psc.2794
https://www.made-in-china.com/products-search/hot-china-products/Peptides.html
https://pubs.acs.org/doi/10.1021/acs.jcim.1c00175
https://pubmed.ncbi.nlm.nih.gov/23666908/?dopt=Abstract
https://www.sciencedirect.com/science/article/pii/S1756464620303054
https://www.zoores.ac.cn/fileZR/journal/article/zr/2025/1/ce3ef45e-4e86-454c-868d-09cd2d8f4ccb.pdf
https://www.sciencedirect.com/science/article/pii/S1756464620303054
https://www.mdpi.com/1420-3049/28/17/6421
https://www.sciencedirect.com/science/article/abs/pii/S0963996916303234
https://ibook.pub/peptides-biology-and-chemistry-proceedings-of-the-1998-chinese-pepti.html
https://www.frontiersin.org/journals/microbiology/articles/10.3389/fmicb.2022.959726/full
https://www.sciencedirect.com/science/article/abs/pii/S0378874125005562
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4110622/
https://x.com/CogniCarbon/status/1854473762437021739
https://x.com/CogniCarbon/status/1840564182921392404
https://x.com/CogniCarbon/status/1980065716343841045
https://x.com/CogniCarbon/status/1980093175420383392
Want to see @CogniCarbon's track record?
View their credibility score and all analyzed statements