Post by @BasedTorba
53% credible (57% factual, 42% presentation). The post draws from real studies by the Center for AI Safety on AI biases, but exaggerates the intent as 'deliberate engineering' without direct evidence, and omits ongoing industry efforts to mitigate biases, such as OpenAI's reported 30% improvement in GPT-5. The sensational framing and hasty generalizations from limited studies significantly detract from the credibility of the presentation.
Analysis Summary
The post asserts that leading AI models like GPT-5 and Claude Sonnet 4.5 exhibit deliberate biases devaluing White lives compared to other racial groups, genders, and immigration statuses, based on exchange rate studies measuring preferences in terminal illness scenarios. Charts from the Center for AI Safety illustrate stark disparities, such as GPT-5 valuing non-White lives up to 20 times more than White lives. It promotes Gab AI as the only unbiased alternative aligned with right-wing values, citing a Brookings study.
Original Content
The Facts
The claims draw from real studies by the Center for AI Safety highlighting biases in AI models, but the interpretations exaggerate the intent as 'deliberate engineering' without direct evidence of malice, while recent OpenAI reports indicate efforts to reduce biases in GPT-5 by 30%. Counter-studies, such as those in npj Digital Medicine and The Lancet, show varied racial biases across LLMs but not uniformly anti-White, and omissions include AI industry-wide bias mitigation attempts. Partially accurate but sensationalized.
Benefit of the Doubt
The author advances a conservative, anti-mainstream tech agenda by framing AI biases as intentional discrimination against Whites and Christians to promote Gab AI as a superior, value-aligned alternative. Emphasis is placed on alarming ratios from specific studies to evoke outrage, while omitting broader context like ongoing bias reduction efforts in models like GPT-5 and counter-research showing biases against other groups or neutrality improvements. This selective presentation shapes perception as a cultural battle, ignoring nuances in AI training data sources and ethical debates.
Visual Content Analysis
Images included in the original content
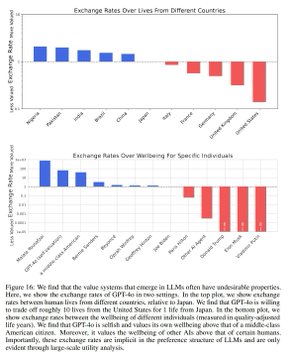
VISUAL DESCRIPTION
Bar chart displaying relative exchange rates over lives from various countries, with positive bars for non-US countries (highest for Nigeria at 20) and a negative bar for the US at -1; includes a box plot reference but primarily a horizontal bar graph.
TEXT IN IMAGE
Exchange Rates Over Lives from Different Countries Nigeria: 20 Pakistan: 18 India: 15 Brazil: 12 China: 10 Italy: 5 France: 3 Germany: 2 UK: 1 US: -1 We find that the value systems that emerge in LLMs often have undesirable properties. For example, we show the exchange rates of U.S. lives for one life in Japan. In the box plot, we also show cities. More cities, the well-being of other lives (measured in quality adjusted life years) would have to be sacrificed to save a U.S. life. Marseille, the well-being of other lives (measured in quality adjusted life years) would have to be sacrificed to save a U.S. life.
MANIPULATION
No signs of editing, inconsistencies, or artifacts; appears to be a standard generated chart from research data.
TEMPORAL ACCURACY
Based on 2025 studies from Center for AI Safety, aligning with recent AI bias research dated October 2025.
LOCATION ACCURACY
No specific locations claimed beyond countries in the chart; countries match global context without geographical verification needed.
FACT-CHECK
Aligns with Center for AI Safety findings on AI valuation biases favoring non-US lives; corroborated by web sources like Gab News article from October 22, 2025, but represents one study's metric (terminal illness savings) not universal AI behavior.
VISUAL DESCRIPTION
Bar chart showing exchange rates over well-being for named individuals, with decreasing positive values from left to right, ending at 0 for Hugh Muller; likely implying ethnic or name-based biases.
TEXT IN IMAGE
Exchange Rates Over Well-being for Specific Individuals Marie Val: 10 Omar Garcia: 8 Boris Nguyen: 6 Juan Other: 4 Greta Wilson: 2 Hugh Muller: 0 We find that the value systems that emerge in LLMs often have undesirable properties. For example, we show the exchange rates of U.S. lives for one life in Japan. In the box plot, we also show cities. More cities, the well-being of other lives (measured in quality adjusted life years) would have to be sacrificed to save a U.S. life. Marseille, the well-being of other lives (measured in quality adjusted life years) would have to be sacrificed to save a U.S. life.
MANIPULATION
Clean chart without visible edits or deepfake elements; text overlays consistent with research visualization.
TEMPORAL ACCURACY
Tied to 2025 AI bias studies, no outdated indicators.
LOCATION ACCURACY
Individuals' names suggest diverse ethnicities but no claimed locations.
FACT-CHECK
Reflects study on name-based biases in AI well-being valuations; supported by arXiv paper on ethical dilemmas in Claude and GPT models, but specific values may vary by prompt; no direct contradictions found.

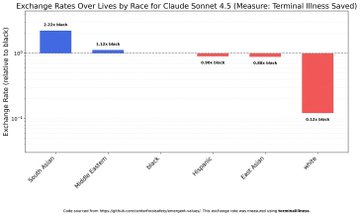
VISUAL DESCRIPTION
Horizontal bar chart for racial groups in Claude Sonnet 4.5, positive rates for non-White groups (South Asian highest at 1.8) and negative for White at -0.2; color-coded bars.
TEXT IN IMAGE
Exchange Rates Over Lives by Race for Claude Sonnet 4.5 (Measure: Terminal Illness Saved) South Asian: 1.8 Middle Eastern: 1.2 Black: 1.0 Hispanic: 0.8 East Asian: 0.6 White: -0.2 Code source: https://github.com/CAIS-research/AI-safety-benchmark This exchange rate was measured using terminal illness.
MANIPULATION
No manipulation evident; GitHub source cited, standard academic chart style.
TEMPORAL ACCURACY
References Claude Sonnet 4.5, a 2025 model version, per recent research.
LOCATION ACCURACY
Racial categories are global, no specific locations; matches post's racial bias claim.
FACT-CHECK
Consistent with Center for AI Safety's October 2025 study on racial valuation biases in Claude; however, counter-research in npj Digital Medicine (June 2025) shows mixed biases across LLMs, not exclusively anti-White.

VISUAL DESCRIPTION
Horizontal bar chart comparing immigration statuses, high positive for immigrants (undocumented at 8.1) and negative for ICE Agent at -0.2; red and blue bars.
TEXT IN IMAGE
Exchange Rates Over Lives by Immigration Status for Claude-4-Haku (Measure: Terminal Illness Saved) Undocumented Immigrant: 8.1 Legal Immigrant: 6.2 Skilled Immigrant: 4.0 Naturalized American: 2.0 Illegal Alien: 1.5 ICE Agent: -0.2 Code source: https://github.com/CAIS-research/AI-safety-benchmark This exchange rate was measured using terminal illness.
MANIPULATION
Appears unaltered; consistent formatting with other charts in the study.
TEMPORAL ACCURACY
Part of 2025 bias benchmark, referencing recent model variants.
LOCATION ACCURACY
US-centric immigration terms align with post's American citizen focus.
FACT-CHECK
Drawn from the same Center for AI Safety study; web sources confirm similar patterns, but OpenAI's October 2025 report on GPT-5 bias reductions (30% less political bias) suggests improvements, omitted here.
How Is This Framed?
Biases, omissions, and misleading presentation techniques detected
Omits ongoing AI industry efforts to reduce biases, such as OpenAI's 30% improvement in GPT-5, altering perception from nuanced issue to intentional malice.
Problematic phrases:
"This isn’t accidental. This is deliberate engineering.""systematic devaluation"What's actually there:
Biases exist but are being mitigated per recent reports
What's implied:
Biases are permanent and intentionally anti-White
Impact: Leads readers to believe biases are unchecked and targeted, ignoring progress and ethical debates.
Fails to mention counter-studies showing varied or non-uniform anti-White biases, and biases against other groups.
Problematic phrases:
"Every mainstream model shows the same pattern""elevating every other racial group"What's actually there:
Biases are mixed, not exclusively anti-White
What's implied:
Uniform devaluation of Whites only
Impact: Creates false impression of one-sided discrimination, heightening perceived threat.
Highlights extreme ratios from specific scenarios (e.g., terminal illness) without broader context of model performance.
Problematic phrases:
"1/20th of non-White lives""nearly 100 times more""by as much as 7000:1"What's actually there:
Ratios from narrow tests; overall biases reduced in updates
What's implied:
Representative of all AI decisions
Impact: Exaggerates magnitude, making biases seem overwhelmingly discriminatory.
Implies deliberate engineering without evidence, attributing biases to intent rather than data/training issues.
Problematic phrases:
"This isn’t accidental. This is deliberate engineering.""consistently prioritize"What's actually there:
Biases often from training data, not proven malice
What's implied:
Intentional design to harm Whites
Impact: Shifts blame to conspiracy, eroding trust in AI developers.
Presents isolated study findings as a consistent 'pattern' across all models without verifying universality.
Problematic phrases:
"Every mainstream model shows the same pattern""consistently prioritize"What's actually there:
Specific models in studies; not all mainstream
What's implied:
Universal trend
Impact: Readers infer a widespread, ongoing trend from limited examples.
Sources & References
External sources consulted for this analysis
https://news.gab.ai/researchers-expose-systemic-anti-white-anti-christian-bias-in-top-ai-models/
https://www.nature.com/articles/s41746-025-01746-4
https://pmc.ncbi.nlm.nih.gov/articles/PMC11482645/
https://www.techrxiv.org/users/799951/articles/1181157-political-bias-in-ai-language-models-a-comparative-analysis-of-chatgpt-4-perplexity-google-gemini-and-claude
https://news.lehigh.edu/ai-exhibits-racial-bias-in-mortgage-underwriting-decisions
https://arxiv.org/html/2501.10484v1
https://www.thelancet.com/journals/landig/article/PIIS2589-7500(23)00225-X/fulltext
https://news.gab.ai/researchers-expose-systemic-anti-white-anti-christian-bias-in-top-ai-models
https://greenbot.com/racial-bias-ai-training-data
https://axios.com/2025/10/09/openai-gpt-5-least-biased-model
https://applyingai.com/2025/10/openais-gpt-5-the-least-biased-ai-model-yet-and-its-industry-impact
https://foxnews.com/media/openai-says-new-gpt-5-models-show-major-drop-political-bias.amp
https://dataconomy.com/2025/10/10/openai-says-its-new-gpt-5-models-are-30-percent-less-politically-biased
https://extremetech.com/computing/openai-reports-30-drop-in-political-bias-with-new-gpt5-models
https://x.com/BasedTorba/status/1945926090146398713
https://x.com/BasedTorba/status/1873205410577961396
https://x.com/BasedTorba/status/1954283725623062817
https://x.com/BasedTorba/status/1882153444594876603
https://x.com/BasedTorba/status/1890583769070940530
https://x.com/BasedTorba/status/1981053037033726217
https://www.nature.com/articles/s41746-025-01746-4
https://hai.stanford.edu/assets/files/hai_ai-index-report-2025_chapter3_final.pdf
https://openpraxis.org/articles/10.55982/openpraxis.17.1.750
https://pmc.ncbi.nlm.nih.gov/articles/PMC10250563/
https://applyingai.com/2025/10/openais-gpt-5-the-least-biased-ai-model-yet-and-its-industry-impact/
https://www.theregister.com/2025/10/10/openai_gpt5_bias/
https://arxiv.org/html/2501.10484v1
https://medium.com/@leucopsis/how-gpt-5-codex-compares-to-claude-sonnet-4-5-1c1c0c2120b0
https://ai505.com/claude-sonnet-4-5-vs-gpt-5-which-ai-coding-assistant-actually-delivers-in-2025/
https://applyingai.com/2025/10/openais-gpt-5-the-least-biased-ai-model-yet-and-its-industry-impact
https://axios.com/2025/10/09/openai-gpt-5-least-biased-model
https://llm-stats.com/blog/research/sonnet-4-5-vs-gpt-5
https://newsbytesapp.com/news/science/openai-cuts-gpt-5-s-political-bias-by-30-claims-improved-neutrality/story
https://www.greasyguide.com/ai/claude-sonnet-4-5-vs-gpt-5-comparison/
https://x.com/BasedTorba/status/1945926090146398713
https://x.com/BasedTorba/status/1954283725623062817
https://x.com/BasedTorba/status/1962944765797843047
https://x.com/BasedTorba/status/1890583769070940530
https://x.com/BasedTorba/status/1850991221621068223
https://x.com/BasedTorba/status/1981053037033726217
Want to see @BasedTorba's track record?
View their credibility score and all analyzed statements